
Be mindful of advice. Give an ear to those offering it. Just be mindful, there is no need to accept the advice, but it is wise to at least listen.
1 DBA's Professional Blog

Be mindful of advice. Give an ear to those offering it. Just be mindful, there is no need to accept the advice, but it is wise to at least listen.

Every Database has a DBO or database owner set. Sometimes the owner is invalid, while most of the time the DBO is perfectly normal. It is easy to ignore whether a valid DBO is set or not. And then something breaks and you have to validate it. This article addresses the easy fix to validate the DBO.

Having a Database Owner is not something that most people think about until something breaks. Usually, people will just kind of ignore it because it is just so innocuous and uncommon for the owner to not be “present”.
Excessive memory grants are extremely problematic in SQL Server. These excessive grants do not just happen out of the blue. Memory grants are directly linked to the queries.
Queries will fail. That is as inevitable as death and taxes. This article demonstrates how to find some truly horrible queries.
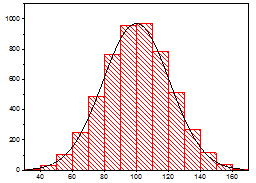
This article demonstrates a more comprehensive method to audit changes to statistics. This method involves the use of Extended Events.

By combining the raw power of the Extended Events engine in SQL Server with the Blocked Process Report, we are able to achieve real value in blocking monitoring.

In this article, I have shown the importance of performing three different validation tests against your Availability Group Endpoints. Each test also demonstrates what can be run in the event the validation test fails.
XEvents is here to stay and is a powerful tool for ALL of your SQL implementations – whether they be Azure SQL or the traditional on-premises SQL Server.

XEvents is a power tool in SQL Server. While it may still be rather immature in the world of SSAS, it still has a great deal of benefit and power to offer.